파이썬에서 얕은 목록을 평탄화하기
이 질문에는 이미 답변이 있습니다.
- 목록 목록에서 단순 목록을 만드는 방법 45 답변
목록 이해를 통해 반복 가능한 목록을 평평하게하는 간단한 방법이 있습니까? 아니면 실패하면 성능과 가독성의 균형을 유지하면서 이와 같이 얕은 목록을 평평하게하는 가장 좋은 방법은 무엇입니까?
다음과 같이 중첩 된 목록 이해로 그러한 목록을 평면화하려고했습니다.
[image for image in menuitem for menuitem in list_of_menuitems]
그러나 나는 NameError거기 에서 다양성 에 어려움을 겪 습니다 name 'menuitem' is not defined. 인터넷 검색을하고 Stack Overflow를 둘러 본 후 원하는 결과를 얻었습니다 reduce.
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
그러나 list(x)x는 Django QuerySet객체 이기 때문에 호출이 필요하기 때문에이 메서드는 읽을 수 없습니다 .
결론 :
이 질문에 기여한 모든 분들께 감사드립니다. 여기 내가 배운 것에 대한 요약이 있습니다. 다른 사람들이 이러한 관찰을 추가하거나 수정하려는 경우를 대비하여 이것을 커뮤니티 위키로 만들고 있습니다.
내 원래의 축소 진술은 중복되며 다음과 같이 작성하는 것이 좋습니다.
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
이것은 중첩 된 목록 이해에 대한 올바른 구문입니다 (Brilliant summary dF !) :
>>> [image for mi in list_of_menuitems for image in mi]
그러나 이러한 방법 중 어느 것도 다음을 사용하는 것만 큼 효율적이지 않습니다 itertools.chain.
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
그리고 @cdleary 메모와 같이 다음과 같이 사용하여 연산자 마법을 피하는 것이 더 나은 스타일 일 것입니다 chain.from_iterable.
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
플랫 화 된 버전의 데이터 구조를 반복하고 색인 가능한 시퀀스가 필요없는 경우 itertools.chain 및 company를 고려하십시오 .
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
그것은 Django의 iterable을 포함 해야하는 반복 가능한 모든 것에서 작동 QuerySet하며, 질문에 사용하고있는 것으로 보입니다.
편집 : reduce는 항목을 확장중인 목록에 복사하는 것과 동일한 오버 헤드를 가지기 때문에 아마도 reduce만큼 좋습니다. 마지막에 chain실행하면이 (같은) 오버 헤드 만 발생합니다 list(chain).
메타 편집 : 실제로는 임시로 원본을 확장 할 때 생성 한 임시 목록을 버리기 때문에 질문에서 제안한 솔루션보다 오버 헤드가 적습니다.
편집 : 로 JF 세바스찬 말한다는 itertools.chain.from_iterable 포장 해체 및 방지하기 위해 그것을 사용해야 방지 *마법을하지만, timeit의 응용 프로그램 을 보여줍니다 무시할 성능 차이를.
당신은 거의 그것을 가지고 있습니다! 내포 된 목록 이해를 수행 하는 방법for 은 일반적인 내포 된 for명령문 과 동일한 순서로 명령문 을 배치하는 것입니다 .
따라서이
for inner_list in outer_list:
for item in inner_list:
...
에 해당
[... for inner_list in outer_list for item in inner_list]
그래서 너는 원해
[image for menuitem in list_of_menuitems for image in menuitem]
@ S.Lott : 당신은 timeit 앱을 작성하도록 영감을주었습니다.
나는 또한 파티션 수 (컨테이너 목록 내의 반복자 수)에 따라 달라질 것이라고 생각했습니다. 귀하의 의견에는 30 개의 항목 중 몇 개의 파티션이 있는지 언급하지 않았습니다. 이 줄거리는 다양한 수의 파티션으로 매 실행마다 수천 개의 항목을 병합합니다. 항목은 파티션간에 균등하게 분배됩니다.
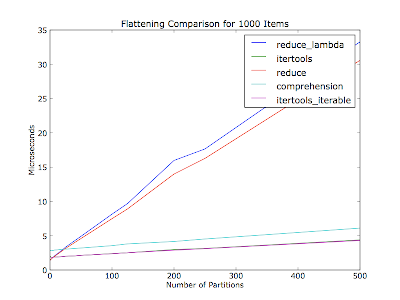
코드 (Python 2.6) :
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
편집 : 커뮤니티 위키로 만들기로 결정했습니다.
참고 : METHODS 아마도 데코레이터가 쌓여 있어야하지만 사람들 이이 방법을 읽는 것이 더 쉬울 것이라고 생각합니다.
sum(list_of_lists, []) 그것을 평평하게 할 것입니다.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
이 솔루션은 다른 솔루션의 일부 (모두?)가 제한되는 "목록 목록"깊이뿐만 아니라 임의의 중첩 깊이에 적용됩니다.
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
임의의 깊이 중첩을 허용하는 재귀입니다. 물론 최대 재귀 깊이에 도달 할 때까지 ...
성능 결과. 수정되었습니다.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
30 개 항목의 2 단계 목록을 1000 배로 평면화했습니다.
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
감소는 항상 좋지 않은 선택입니다.
Python 2.6에서는 다음을 사용합니다 chain.from_iterable().
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
중간 목록을 작성하지 않습니다.
와 혼동이있는 것 같습니다 operator.add! 두 개의 목록을 함께 추가 할 때 올바른 용어는입니다 concat. operator.concat사용해야합니다.
기능적이라고 생각하면 다음과 같이 쉽습니다. :
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
시퀀스 유형이 축소되는 것을 알 수 있으므로 튜플을 공급하면 튜플이 다시 나타납니다. 목록으로 시도해 봅시다 ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
아하, 당신은 목록을 다시 얻는다.
성능은 어떻습니까 ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable은 꽤 빠릅니다! 그러나 concat으로 축소하는 것은 비교할 수 없습니다.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
내 머리 꼭대기에서 람다를 제거 할 수 있습니다.
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
또는 목록 작성이 이미 있으므로 맵을 제거하십시오.
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
이것을 목록의 합계로 표현할 수도 있습니다.
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
다음은 목록 이해를 사용하는 올바른 솔루션입니다 (뒤에 있음).
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
귀하의 경우에는
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
또는 당신은 사용 join하고 말할 수 있습니다
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
두 경우 모두 문제는 for루프 의 중첩이었습니다 .
다음은 여러 레벨의 목록에서 작동하는 버전입니다 collectons.Iterable.
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
납작 해 보셨습니까? 에서 (서열, scalarp을 =) matplotlib.cbook.flatten ?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
업데이트 나에게 또 다른 아이디어를 주었다.
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
재귀가 깊어 질 때 얼마나 효과적인지 테스트하려면 얼마나 깊습니까?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
"flattenlist"에 베팅 할 것입니다. matploblib.cbook에서 "flatten"사용으로 수율 생성기 및 빠른 결과를 원하지 않는 한 matploblib 대신 이것을 오랫동안 사용하려고합니다.
이것은 빠릅니다.
- 그리고 여기 코드가 있습니다
:
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
이 버전은 생성기입니다. 목록을 원하면 조정하십시오.
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
조건을 만족하는 것을 병합하려는 경우 술어를 추가 할 수 있습니다.
파이썬 요리 책에서 가져온
내 경험상 목록 목록을 평평하게하는 가장 효율적인 방법은 다음과 같습니다.
flat_list = []
map(flat_list.extend, list_of_list)
다른 제안 된 방법과의 일부 시간 비교
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
이제 더 긴 하위 목록을 처리 할 때 효율성이 향상되었습니다.
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
그리고이 방법은 모든 반복 객체와 함께 작동합니다.
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
반복 불가능한 요소 또는 깊이가 2보다 큰 복잡한 목록을 평면화 해야하는 경우 다음 기능을 사용할 수 있습니다.
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
list()함수 를 사용하여 목록으로 변환 할 수있는 생성기 객체를 반환 합니다. 주의하는 것이 yield from구문은 python3.3에서 사용할 시작,하지만 당신은 대신 명시 적 반복을 사용할 수 있습니다.
예:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
def is_iterable(item):
return isinstance(item, list) or isinstance(item, tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
테스트:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
는 어때:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
그러나 Guido는 가독성을 떨어 뜨리므로 한 줄의 코드에서 너무 많은 성능을 수행하지 않는 것이 좋습니다. 한 줄에서 여러 줄로 원하는 것을 수행함으로써 최소한의 성능 향상이 있습니다.
pylab은 flatten을 제공합니다 : numpy flatten에 대한 링크
내장 된 간단한 단일 라이너를 찾고 있다면 다음을 사용할 수 있습니다.
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
보고
[1, 2, 3, 4, 5, 6]
목록의 각 항목이 문자열이고 해당 문자열 내의 문자열이 ''대신 ""를 사용하는 경우 정규식 ( re모듈)을 사용할 수 있습니다
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
위의 코드는 in_list를 문자열로 변환하고 정규 표현식을 사용하여 따옴표 내의 모든 하위 문자열 (예 : 목록의 각 항목)을 찾아 목록으로 뱉어냅니다.
간단한 대안은 numpy의 concatenate 를 사용하는 것이지만 내용을 부동으로 변환합니다.
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
파이썬 2 또는 3에서 이것을 달성하는 가장 쉬운 방법은을 사용하여 모프 라이브러리를 사용하는 것 pip install morph입니다.
코드는 다음과 같습니다
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
Python 3.4 에서는 다음 을 수행 할 수 있습니다.
[*innerlist for innerlist in outer_list]
참고 URL : https://stackoverflow.com/questions/406121/flattening-a-shallow-list-in-python
'Programming' 카테고리의 다른 글
| 하나의 지점 만 복제 (0) | 2020.02.25 |
|---|---|
| IPv4에 허용되는 최대 TCP / IP 네트워크 포트 번호는 무엇입니까? (0) | 2020.02.25 |
| Sublime Text에서 선택을 소문자 (또는 대문자)로 변환 하시겠습니까? (0) | 2020.02.25 |
| Node.js에서 사용하지 않는 패키지를 제거하거나 제거하는 npm 명령 (0) | 2020.02.25 |
| ERROR 2002 (HY000) : '/var/run/mysqld/mysqld.sock'소켓을 통해 로컬 MySQL 서버에 연결할 수 없습니다 (2). (0) | 2020.02.25 |